

今回は,機械学習のライブラリである,scikit-learnを使って,ラズパイ上で簡単な機械学習を行いたいと思います.
目次
環境
| OS | rasbian version4.19 |
| プログラミング言語 | Python3.7.3 |
| 機械学習ライブラリ | scikit-learn |
sikit-learnの導入
機械学習を行いたいので,機械学習用ライブラリ[scikit-learn]をインストールします.
ターミナルで下のコードを入力します.
$ sudo apt-get install python3-sklearn準備
データ
今回は,scikit-learn に元々データセットとして入っている,アヤメの分類を行います.
アヤメは英名でirisといい,種類が多く,人間でも見分けることが大変です.

このどれか3つに分けるために,次の4つの特徴量を用います.
- 外花被片の長さ
- 外花被片の幅
- 内花被片の長さ
- 内花被片の幅
これらのデータがscikit-learnのデータセットに入っているので,この4次元ベクトルをサポートベクトルマシンを用いて分類します.
サポートベクターマシンについて
今回用いる機械学習は,サポートベクターマシンです.
これは,以下の図のように2つのクラスに分類する場合,それらがきれいに分かれるような境界線を求める式です.
線形で分離できるものとしたときの境界線は,下図のように直線となります.
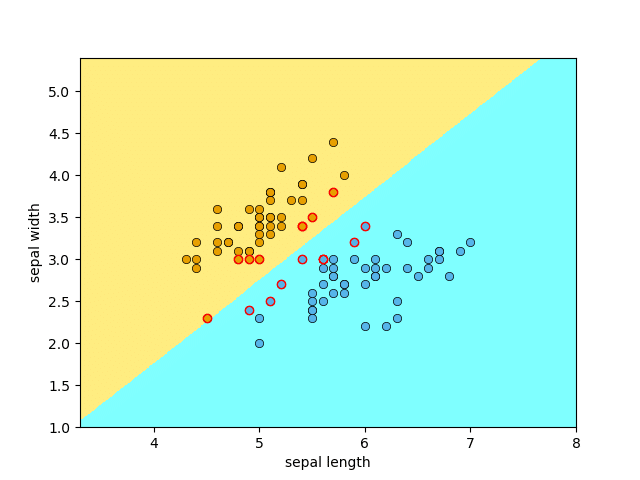
これは特徴量が2つの2次元ベクトルで,分類も2種類だけですが,アヤメも同じ概念で分類するものだと考えてください.
実際にやってみよう
Pythonコード
アヤメを分類するPythonのコードは以下のようになります.
from sklearn import datasets, svm
# アヤメのデータをロードし、変数irisに格納
iris = datasets.load_iris()
# 特徴量のセットを変数Xに、正解データを変数yに格納
X = iris.data
y = iris.target
# 分類用にサポートベクトルマシンを用意
clf = svm.SVC(decision_function_shape="ovr",kernel="linear")
# データに最適化
clf.fit(X, y)
# データを分類器に与え、予測を得る
result = clf.predict(X)
print('教師データ')
print(y)
print('機械学習による予測')
print(result)
# データ数をtotalに格納
total = len(X)
# ターゲット(正解)と予測が一致した数をsuccessに格納
success = sum(result==y)
# 正解率をパーセント表示
print('正解率')
print(100.0*success/total)このコードは,『Raspberry piではじめる機械学習』を参考にしたものです.
データ構造
iris = datasets.load_iris()
X = iris.data
y = iris.targetdatasetsモジュールのload_irisメソッドで,データを変数irisに格納します.
データ構造は,次の図のようになっています.

特徴量のデータはiris.data,正解データはiris.targetで取り出せます.
サポートベクターマシン
clf = svm.SVC(decision_function_shape="ovr",kernel="linear")svmモジュールのSVCクラスのインスタンスを生成する文です.
多クラス分類のため,ovr( one-versus-the-rest )で識別します.また,カーネルは線形とします.
clf.fit(X, y)SVCクラスのfitメソッドを実行し,特徴量と正解データを用いて,モデルを学習します.
clf.predict(X)SVCクラスのpredictメソッドを実行し,特徴量だけを与えて,正解を予測します.
今回は簡単のため,学習に用いた特徴量と予測に用いた特徴量が同じですが,実際には違ったものを用います.
結果
正解確率は,99.3%でした.
よって,この線形サポートベクターマシンでは,完全には線形分離できなかったことが分かります.
まとめ
今回は,線形サポートベクターマシンを用いて,アヤメの分類をやってみました.
今後もラズパイ上で,機械学習をどこまで行えるのかを探っていきたいと思います.
ラズパイで機械学習を行ってみたいと思った方は,ぜひこの本がおすすめです.









コメントを残す