

以前ラズパイで行ったscikit-learnでのアヤメの分類のパート2ということで,2次元データの描画について解説を行いたいと思います.
目次
コード
今回用いるコードは以下のようになります.
# -*- coding: utf-8 -*-
from sklearn import datasets, svm
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# アヤメのデータをロードし、変数irisに格納
iris = datasets.load_iris()
# 特徴量のセットを変数Xに、ターゲットを変数yに格納
X = iris.data
y = iris.target
# 特徴量を外花被片の長さ(sepal length)と幅(sepal width)の
# 2つのみに制限(2次元で考えるため)
X = X[:,:2]
# ターゲットは2 (iris virginica) でないもの,
# つまり iris setosa (0) と iris versicolor (1) のみを対象とする
# (領域の2分割)
X = X[y!=2]
y = y[y!=2]
# 分類用にサポートベクトルマシン (Support Vector Classifier) を用意
clf = svm.SVC(C=1.0, kernel='linear')
# データに最適化
clf.fit(X, y)
##### 分類結果を背景の色分けにより表示
# 外花被片の長さ(sepal length)と幅(sepal width)の
# 最小値と最大値からそれぞれ1ずつ広げた領域を
# グラフ表示エリアとする
x_min = min(X[:,0]) - 1
x_max = max(X[:,0]) + 1
y_min = min(X[:,1]) - 1
y_max = max(X[:,1]) + 1
# グラフ表示エリアを縦横500ずつのグリッドに区切る
# (分類クラスに応じて背景に色を塗るため)
XX, YY = np.mgrid[x_min:x_max:500j, y_min:y_max:500j]
# グリッドの点をscikit-learn用の入力に並べなおす
Xg = np.c_[XX.ravel(), YY.ravel()]
# 各グリッドの点が属するクラス(0か1)の予測をZに格納
Z = clf.predict(Xg)
# Zをグリッド上に並べなおす
Z = Z.reshape(XX.shape)
# クラス0 (iris setosa) が薄オレンジ (1, 0.93, 0.5, 1)
# クラス1 (iris versicolor) が水色 (0.5, 1, 1, 1)
cmap01 = ListedColormap([(0.5, 1, 1, 1), (1, 0.93, 0.5, 1)])
# 背景の色を表示
plt.pcolormesh(XX, YY, Z==0, cmap=cmap01)
# 軸ラベルを設定
plt.xlabel('sepal length')
plt.ylabel('sepal width')
##### ターゲットに応じた色付きでデータ点を表示
# iris setosa (y=0) のデータのみを取り出す
Xc0 = X[y==0]
# iris versicolor (y=1) のデータのみを取り出す
Xc1 = X[y==1]
# iris setosa のデータXc0をプロット
plt.scatter(Xc0[:,0], Xc0[:,1], c='#E69F00', linewidths=0.5, edgecolors='black')
# iris versicolor のデータXc1をプロット
plt.scatter(Xc1[:,0], Xc1[:,1], c='#56B4E9', linewidths=0.5, edgecolors='black')
# サポートベクトルを取得
SV = clf.support_vectors_
print(SV)
# サポートベクトルの点に対し、赤い枠線を表示
plt.scatter(SV[:,0], SV[:,1], c=(0,0,0,0), linewidths=1.0, edgecolors='red')
# 描画したグラフを表示
plt.show()このコードは 『Raspberry piではじめる機械学習』を参考にしたものです.
以下のサイトでソースコードをダウンロードできます.
http://bluebacks.kodansha.co.jp/books/9784065020524/appendix/
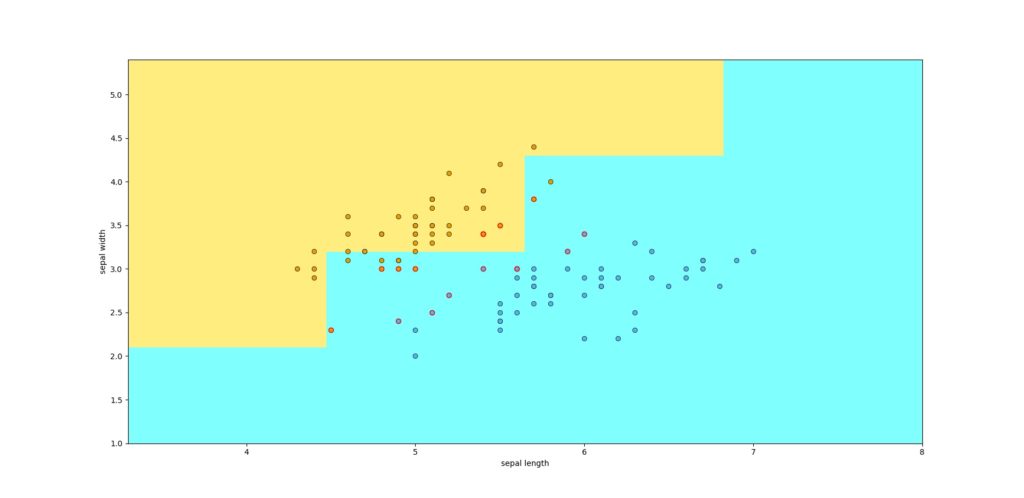
結果
上記のコードの結果はこのようになります.

このように,二次元画像として,色を分けてきれいに表示できます.

背景も色が塗れてるワン!
コード解説
用いるデータ
scikit-learnのirisデータは,4つの特徴量がありますが,4次元を表現することができないため,今回は2つの特徴量を用います.
4つの特徴量を2つの特徴量に次元削除を行っているのが,16行目です.
また,デフォルトでは3つのirisに分類するため,正解データも0,1,2というように3種類あります.今回は,1本の境界線で分離させたいため,正解データが2であるirisを削除します.
3つの分類を2つの分類とするコードが21,22行目です.
メッシュグリッドの生成
画像として出力するために,座標を定義する必要があります.
x座標,y座標をメッシュ格子として定義します.numpy.mgridでメッシュ配列を作ります.
mgrid[最小:最大:個数j]で何個メッシュを作るかを指定できます.今回は500×500のメッシュ格子を作ります.
もしこの値が小さすぎると,下の画像のように荒くなります.これは個数を5とした場合です.

個数が5個だと,だいぶ荒いんダナ.学習学習ット
XX, YY = np.mgrid[x_min:x_max:500j, y_min:y_max:500j]
Xg = np.c_[XX.ravel(), YY.ravel()]メッシュデータを学習用の入力データに変換します.
XX,YYはそれぞれ2次元データとなっていて,それぞれを1次元データに変換し,numpy.c_で2つの1次元データを結合します.それによって,すべての座標での予測を学習モデルで実行できます.
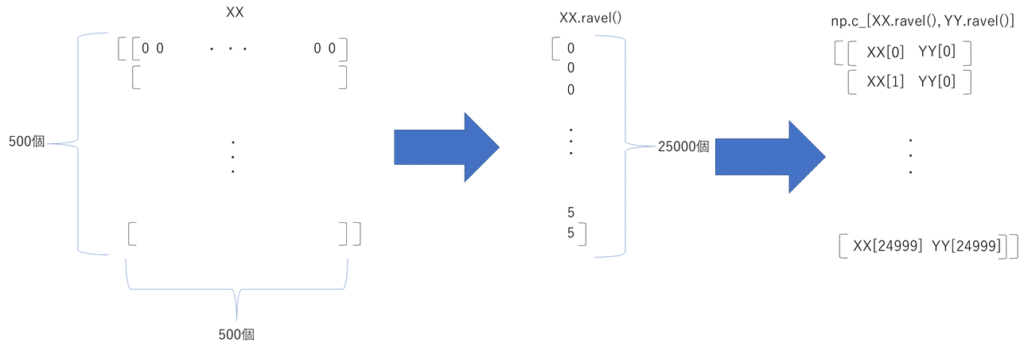
※上の画像の一番右の2列目はYY[0]ではなく,YY[1]です.
背景の色つけ
cmap01 = ListedColormap([(0.5, 1, 1, 1), (1, 0.93, 0.5, 1)])
# 背景の色を表示
plt.pcolormesh(XX, YY, Z==0, cmap=cmap01)続いて,先ほど作成したメッシュマップを元に,色をつけていきます.
matplotlib.colorsモジュールのListedColormapクラスを使います.引数として,rgbもしくはrgbaを与えます.今回はrgbaで薄オレンジと水色を指定します.カラーはここからも様々な色を選ぶことができます.
点のプロット
Xc0 = X[y==0]
Xc1 = X[y==1]
plt.scatter(Xc0[:,0], Xc0[:,1], c='#E69F00', linewidths=0.5, edgecolors='black')
plt.scatter(Xc1[:,0], Xc1[:,1], c='#56B4E9', linewidths=0.5, edgecolors='black')この4行でデータの点をプロットします.
サポートベクトルのプロット
SV = clf.support_vectors_
plt.scatter(SV[:,0], SV[:,1], c=(0,0,0,0), linewidths=1.0, edgecolors='red')サポートベクトルは,境界線を決定するために用いた点のことです.
サポートベクトルは,SVCクラスのsupport_vectors_に格納されていて,取り出すことができます.
これも先ほどと同じように,散布図でプロットし,赤色で協調します.
まとめ
今回は,以前行ったアヤメの分類を,次元と分類する種類を少なくして,視覚的に分かりやすい結果を得ることができました.
以下の本を参考にしたものなので,より機械学習について学んでみたいという方はぜひ読んでみて下さい.

実際に動くものが作れるのは楽しいワン!!
次の記事を読む
次回は,3つのクラスに分類する方法についてまとめていきます.










グラフの可視化ってどうヤルノ?