こんにちは! けい(Twitter)です。
今回は、マイクで取得した音声データをリアルタイムにFFT処理を行い、グラフに表示する方法をまとめていきたいと思います。
目次
必要なもの
Raspberry Pi
今回はラズパイ4を使いました。音声信号のFFT処理は結構重い処理なので、リアルタイム性を求めたい場合はラズパイ4を使った方が良いです。

USBマイク
ラズパイで音声を取得するためのマイクが必要になります。
こちらのマイクで動作確認を行っています。

ステップ⓪:音声信号をラズパイで取得してみる
ラズパイで音声信号をPythonで取得するために必要な準備が2つあります。
- 「Pyaudio」のインストール
- マイクの接続番号の確認
これらの準備は前回の記事でまとめたので参考にしてみてください。
ステップ①:音声信号をFFT
まずは、音声信号をFFTするプログラムを見ていきましょう。
Pythonコード
import pyaudio
import wave
import numpy as np
form_1 = pyaudio.paInt16 # 16-bit resolution
chans = 1 # 1 channel
samp_rate = 44100 # 44.1kHz サンプリング周波数
N = 50
chunk = 1024*N # 2^12 一度に取得するデータ数
record_secs = 3 # 録音する秒数
dev_index = 2 # デバイス番号
wav_output_filename = 'test.wav' # 出力するファイル
sleepTime = 0.0001
audio = pyaudio.PyAudio() # create pyaudio instantiation
# ストリームの作成
stream = audio.open(format = form_1,rate = samp_rate,channels = chans, \
input_device_index = dev_index,input = True, \
frames_per_buffer=chunk)
print("recording")
# 音声の取得とFFT処理
while True:
try:
data = stream.read(chunk)
ndarray = np.frombuffer(data, dtype='int16')
wave_y = np.fft.fft(ndarray)
wave_y = np.abs(wave_y)
except KeyboardInterrupt:
print("Ctrl+Cで停止しました")
break
print("finished recording")
# ストリームの終了
stream.stop_stream()
stream.close()
audio.terminate()
FFT処理
上のプログラムの26行目「data = stream.read(chunk)」で音声データを取り込みます。
この時点ではまだ時系列データです。
これを29行目「wave_y = np.fft.fft(ndarray)」でFFTの計算を行っています。
また、27行目は取得した音声データがbufferオブジェクトなので、ndarray型に変換しています。
たったこれだけのプログラムで、FFTが出来てしまいます。
ステップ②:FFTスペクトラムをリアルタイムにグラフ表示
次は、ステップ①でFFTした音声の周波数成分をリアルタイムに表示してみましょう。
Pythonコード
import pyaudio
import wave
import numpy as np
import matplotlib.pyplot as plt
form_1 = pyaudio.paInt16 # 16-bit resolution
chans = 1 # 1 channel
samp_rate = 44100 # 44.1kHz サンプリング周波数
N = 50
chunk = 1024*N # 2^12 一度に取得するデータ数
record_secs = 3 # 録音する秒数
dev_index = 2 # デバイス番号
wav_output_filename = 'test.wav' # 出力するファイル
sleepTime = 0.0001
audio = pyaudio.PyAudio() # create pyaudio instantiation
# ストリームの作成
stream = audio.open(format = form_1,rate = samp_rate,channels = chans, \
input_device_index = dev_index,input = True, \
frames_per_buffer=chunk)
# x軸
wave_x = np.linspace(0, samp_rate, chunk)
chunk2 = int(chunk/2)
wave_x2 = wave_x[0:chunk2]
print("recording")
# 音声の取得とFFT処理
while True:
try:
# 音声データの取得
data = stream.read(chunk)
ndarray = np.frombuffer(data, dtype='int16')
# FFT
wave_y = np.fft.fft(ndarray)
wave_y = np.abs(wave_y)
wave_y2 = wave_y[0:chunk2]
# リアルタイムにグラフ表示
plt.plot(wave_x2,wave_y2)
plt.draw()
plt.pause(sleepTime)
plt.cla()
except KeyboardInterrupt:
print("Ctrl+Cで停止しました")
break
print("finished recording")
# ストリームの終了
stream.stop_stream()
stream.close()
audio.terminate()
実行結果
コードの実行結果はyoutubeに動画としてまとめています。
また、音声信号を発生させるために、WaveGeneというフリーソフトを使用しています。
リアルタイム表示
Pythonでグラフをリアルタイムに表示する方法は前回の記事でまとめているので、そちらを参考にしてみて下さい。
ライブラリのインストール等必要になります。
ステップ③:特定の周波数を抽出する
FFT解析を行うことによって、時系列データから周波数成分を取り出すことができます。
これによって、周波数成分によって大事な情報が分かったり、ある周波数成分を操作することが可能となります。
今回は音の情報から、ある一定以上の大きさを持つ音を抽出したいと思います。
Pythonコード
import pyaudio
import wave
import numpy as np
import matplotlib.pyplot as plt
form_1 = pyaudio.paInt16 # 16-bit resolution
chans = 1 # 1 channel
samp_rate = 44100 # 44.1kHz サンプリング周波数
N = 50
chunk = 1024*N # 2^12 一度に取得するデータ数
record_secs = 3 # 録音する秒数
dev_index = 2 # デバイス番号
wav_output_filename = 'test.wav' # 出力するファイル
sleepTime = 0.0001
audio = pyaudio.PyAudio() # create pyaudio instantiation
# ストリームの作成
stream = audio.open(format = form_1,rate = samp_rate,channels = chans, \
input_device_index = dev_index,input = True, \
frames_per_buffer=chunk)
# x軸
wave_x = np.linspace(0, samp_rate, chunk)
chunk2 = int(chunk/2)
wave_x2 = wave_x[0:chunk2]
print("recording")
# 音声の取得とFFT処理
while True:
try:
# 音声データの取得
data = stream.read(chunk)
ndarray = np.frombuffer(data, dtype='int16')
# FFT
wave_y = np.fft.fft(ndarray)
wave_y = np.abs(wave_y)
wave_y2 = wave_y[0:chunk2]
# リアルタイムにグラフ表示
plt.plot(wave_x2,wave_y2)
plt.draw()
plt.pause(sleepTime)
plt.cla()
# 周波数抽出
feature = np.where(wave_y2 > 1e8)
feature = feature[0]
print(feature*(samp_rate/chunk))
except KeyboardInterrupt:
print("Ctrl+Cで停止しました")
break
print("finished recording")
# ストリームの終了
stream.stop_stream()
stream.close()
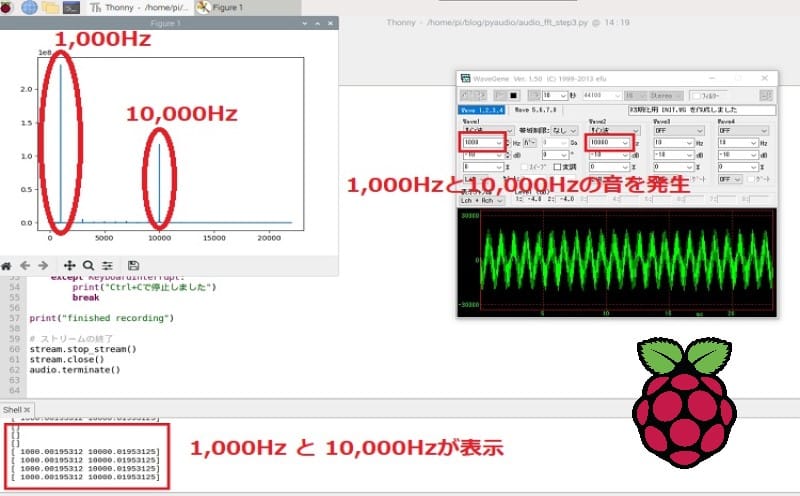
audio.terminate()周波数の抽出
49~51行目でこの処理を行っています。
49行目で、周波数スペクトルが1の8乗よりも大きい周波数成分を取り出しています。
50行目で、返り値がタプルなので、タプルから取り出しています。
51行目で、この時点では’feature’はリストのインデックスなので、それをx軸の周波数に変換させています。
実行結果
1,000Hzと10,000Hzの音を発生させたときの実行結果です。
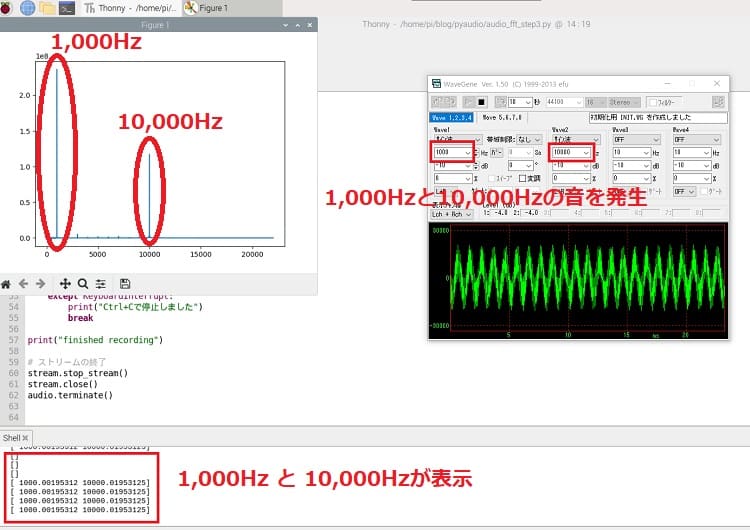
しっかり表示されていることが確認できます。