

こんにちは! けい(Twitter)です.
今回は前回のロボットアームをアップグレードしました!
AI画像認識モデルを使った,ロボットアームの制御を行いたいと思います.
こんな感じの制御をしていきたいと思います.
↓ 前回のロボットアーム
目次
必要なもの
| 部品名 | 用途 |
| Raspberry Pi 3 model B+ https://amzn.to/2JP3w1l | サーボモータの制御 AIの学習,認識 |
| ロボットアーム https://amzn.to/30flZ9r | マニピュレーター |
| Raspberry pi カメラ https://amzn.to/2uYEGVh | 画像の取り込み |
※ロボットアームですが、AliExpressというサイトから買ったほうがお得なので、ぜひ興味のある方はそちらを検討されるのがよいかも知れません。しかし、中国から発送されるので、到着までに1週間以上かかります。
また,カメラはwebカメラなども使うことができますが,プログラムは書き換える必要があります.
もちろん,Raspberry Piは4などのモデルでも動作すると思います.
ロボットアームについて
ラズベリーパイでも制御可能なサーボモータのものを用います.ロボットアームやサーボモータの仕様については以前の記事でまとめているので,そちらをご覧になってください.
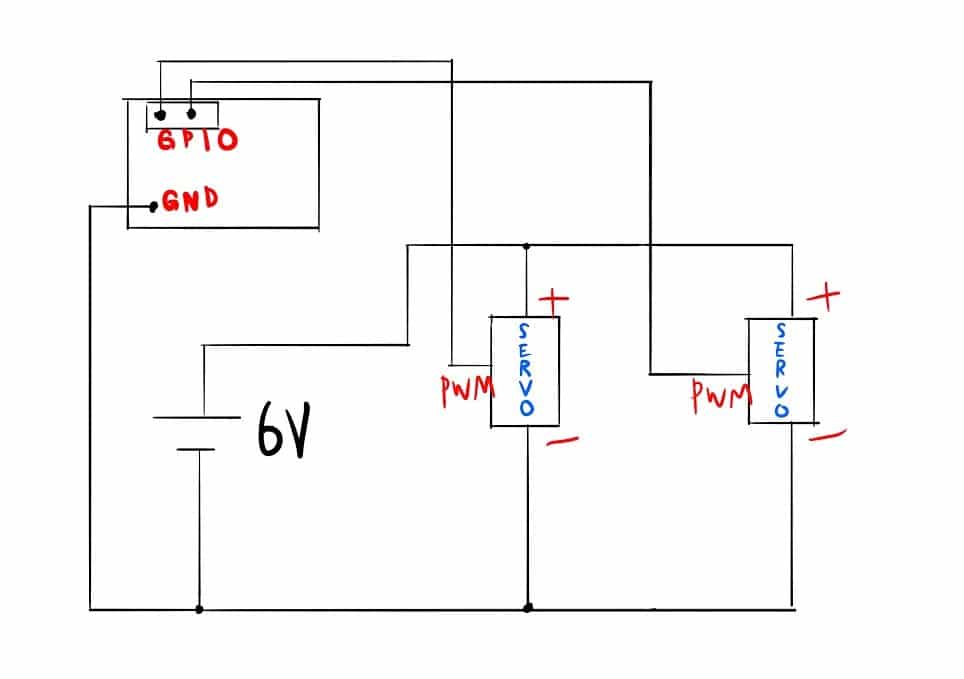
回路
今回はカメラの画像を元に,サーボモータに送るPWM信号を変化させるだけなので,難しくありません.
また,このロボットアームには3つのサーボモータがついていますが,今回は簡単のため水辺軸で動くものと,垂直軸で動くものの2つを用います.
もちろん,3つ目のサーボモータを使って,物を挟んだりすることもできます.
ソースコード
コンセプト
Raspberry Pi上でこれらの事をすべて行うこととします.
- 画像を取り込み,画像処理によって欲しい情報を取り出す.
- ニューラルネットワークの学習モデルを作る
- リアルタイムで画像から,矢印の方向を検出して,ロボットアームの制御を行う.
Raspberry Pi上で,ニューラルネットワークを用いたリアルタイムの機械学習を行うには,画像処理を行って,入力する次元を減らす必要があります.
よって,単に撮った画像をそのままニューラルネットワークに入力するのではなく,Opencvを用いた画像処理を行います.
また,このプログラムはこの本を参考にして作ったものです.もっと詳しく学びたいという方はこちらの本を読んでみてください.


今回はかなりプログラムが長いワン!
頑張ってついてきてワン!
画像の保存
まず初めに,画像を保存するプログラムを作成します.
import picamera
import picamera.array
import cv2
import numpy as np
from scipy import stats
version = cv2.__version__.split(".")
CVversion = int(version[0])
# ファイルの個数を格納する変数
right_file_count = 0
left_file_count = 0
up_file_count = 0
down_file_count = 0
back_file_count = 0
# 二値化された画像を保存するための関数
def save_triangle(mode, img):
global right_file_count
global left_file_count
global up_file_count
global down_file_count
global back_file_count
if mode == 'r':
filename = 'photo/img_right{0:03d}.png'.format(right_file_count)
print('saving {0}'.format(filename))
cv2.imwrite(filename, img)
right_file_count += 1
elif mode == 'l':
filename = 'photo/img_left{0:03d}.png'.format(left_file_count)
print('saving {0}'.format(filename))
cv2.imwrite(filename, img)
left_file_count += 1
elif mode == 'u':
filename = 'photo/img_up{0:03d}.png'.format(up_file_count)
print('saving {0}'.format(filename))
cv2.imwrite(filename, img)
up_file_count += 1
elif mode == 'd':
filename = 'photo/img_down{0:03d}.png'.format(down_file_count)
print('saving {0}'.format(filename))
cv2.imwrite(filename, img)
down_file_count += 1
elif mode == 'b':
filename = 'photo/img_back{0:03d}.png'.format(back_file_count)
print('saving {0}'.format(filename))
cv2.imwrite(filename, img)
back_file_count += 1
with picamera.PiCamera() as camera:
with picamera.array.PiRGBArray(camera) as stream:
# カメラの解像度を320x240にセット
camera.resolution = (320, 240)
# カメラのフレームレートを15fpsにセット
camera.framerate = 15
# ホワイトバランスをfluorescent(蛍光灯)モードにセット
camera.awb_mode = 'fluorescent'
while True:
# stream.arrayにBGRの順で映像データを格納
camera.capture(stream, 'bgr', use_video_port=True)
# 映像データをHSV形式に変換
hsv = cv2.cvtColor(stream.array, cv2.COLOR_BGR2HSV)
# 取り出す色を指定
lower_green = np.array([40,50,50])
upper_green = np.array([70,255,255])
#マスク処理
mask = cv2.inRange(hsv, lower_green, upper_green)
# 以下、最も広い白領域のみを残すための計算
# まず、白領域の塊(クラスター)にラベルを振る
if CVversion == 2:
img_dist, img_label = cv2.distanceTransformWithLabels(255-mask, cv2.cv.CV_DIST_L2, 5)
else:
img_dist, img_label = cv2.distanceTransformWithLabels(255-mask, cv2.DIST_L2, 5)
img_label = np.uint8(img_label) & mask
# ラベル0は黒領域なので除外
img_label_not_zero = img_label[img_label != 0]
# 最も多く現れたラベルが最も広い白領域のラベル
if len(img_label_not_zero) != 0:
m = stats.mode(img_label_not_zero)[0]
else:
m = 0
# 最も広い白領域のみを残す
res = np.uint8(img_label == m)*255
cv2.imshow("frame",stream.array)
cv2.imshow("mask",mask)
cv2.imshow("res",res)
keycode = cv2.waitKey(1)
if keycode == ord("r"):
save_triangle("r", res)
elif keycode == ord("l"):
save_triangle("l", res)
elif keycode == ord("u"):
save_triangle("u", res)
elif keycode == ord("d"):
save_triangle("d", res)
elif keycode == ord("b"):
save_triangle("b", res)
elif keycode == ord("q"):
break
stream.seek(0)
stream.truncate()
cv2.destroyAllWindows()ここでは,主に画像の取り込み,緑色の抽出,最大領域の抽出を行い,それらの流れで処理された画像をキーボードのキー入力によって,クラスごとに保存できるプログラムとなっています.
Raspberry Piのカメラの扱いは以前の記事で解説しているので,ぜひ参考にしてみてください.
ニューラルネットワークの学習
続いて,先ほどのプログラムで保存した画像をニューラルネットワークに学習させるプログラムになります.
# -*- coding: utf-8 -*-
import cv2
import sys
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.externals import joblib
import pylab as plt
# 学習に用いる縮小画像のサイズ
sw = 16
sh = 12
# 学習結果を保存するファイルの決定
if len(sys.argv)!=2:
print('使用法: python vision_learn.py 保存ファイル名.pkl')
sys.exit()
savefile = sys.argv[1]
def getImageVector(img):
# 白い領域(ピクセル値が0でない領域)の座標を集める
nonzero = cv2.findNonZero(img)
# その領域を囲う四角形の座標と大きさを取得
xx, yy, ww, hh = cv2.boundingRect(nonzero)
# 白い領域を含む最小の矩形領域を取得
img_nonzero = img[yy:yy+hh, xx:xx+ww]
# 白い領域を(sw, sh)サイズに縮小するための準備
img_small = np.zeros((sh, sw), dtype=np.uint8)
# 画像のアスペクト比を保ったまま、白い領域を縮小してimg_smallにコピーする
if 4*hh < ww*3 and hh > 0:
htmp = int(sw*hh/ww)
if htmp>0:
img_small_tmp = cv2.resize(img_nonzero, (sw, htmp), interpolation=cv2.INTER_LINEAR)
img_small[int((sh-htmp)/2):int((sh-htmp)/2)+htmp, 0:sw] = img_small_tmp
elif 4*hh >= ww*3 and ww > 0:
wtmp = int(sh*ww/hh)
if wtmp>0:
img_small_tmp = cv2.resize(img_nonzero, (wtmp, sh), interpolation=cv2.INTER_LINEAR)
img_small[0:sh, int((sw-wtmp)/2):int((sw-wtmp)/2)+wtmp] = img_small_tmp
# 0...1の範囲にスケーリングしてからリターンする
return np.array([img_small.ravel()/255.])
# X:画像から計算したベクトル、y:教師データ
X = np.empty((0,sw*sh), float)
y = np.array([], int)
# 右、左、上、下、画像の読み込み
for shape_class in [0, 1, 2, 3, 4]: # 0:右、1:左、2:上 3:下 4:背景
# 画像番号0から999まで対応
for i in range(1000):
if shape_class==0: #右画像
filename = 'photo_robot/img_right{0:03d}.png'.format(i)
elif shape_class==1: #左画像
filename = 'photo_robot/img_left{0:03d}.png'.format(i)
elif shape_class==2: #上画像
filename = 'photo_robot/img_up{0:03d}.png'.format(i)
elif shape_class==3: #下画像
filename = 'photo_robot/img_down{0:03d}.png'.format(i)
elif shape_class==4: #背景画像
filename = 'photo_robot/img_back{0:03d}.png'.format(i)
img = cv2.imread(filename, cv2.IMREAD_GRAYSCALE)
if img is None:
break
print('{0}を読み込んでいます'.format(filename))
#学習用ベクトルの取得
img_vector = getImageVector(img)
#学習用データの格納
X = np.append(X, img_vector, axis=0)
y = np.append(y, shape_class)
# ニューラルネットワークによる画像の学習
clf = MLPClassifier(hidden_layer_sizes=(100, ), max_iter=500, tol=0.0001, random_state=None)
print('学習中…')
clf.fit(X, y)
# 学習結果のファイルへの書き出し
joblib.dump(clf, savefile)
print('学習結果はファイル {0} に保存されました'.format(savefile))
# 損失関数のグラフの軸ラベルを設定
plt.xlabel('time step')
plt.ylabel('loss')
# グラフ縦軸の範囲を0以上と定める
plt.ylim(0, max(clf.loss_curve_))
# 損失関数の時間変化を描画
plt.plot(clf.loss_curve_)
# 描画したグラフを表示
plt.show()このプログラムを実行する時には,ターミナル上でこのようにコマンドを入力します.
$ python pythonファイル名 learn.pklファイル名はこのプログラムのファイル名で,コマンドライン引数として.pklを与えます.もちろん,ここでの名前もlearnではなく何でもいいです.
このプログラムでは主に,先ほど保存した画像を16×12の大きさにリサイズして,scikit-learnのニューラルネットワークライブラリを用いて学習を行っています.
よって,ニューラルネットワークのパーセプトロンの数は以下のようになっています.
| 入力層 | 中間層 | 出力層 |
| 12×16 = 192 | 100 | 5 |
scikit-learnでのニューラルネットワークでの機械学習は以前の記事で解説しているので,興味がある方は参考にしてみてください.
リアルタイムAI認識,ロボットの制御
最後のプログラムは,実際に取り込んだ画像から矢印の方向を検出して,ロボットを動かします.
このプログラムも,先ほどのプログラムと同じようにターミナル上で,コマンドライン引数を学習ファイルとして,実行させます.
また,pigpioというGPIOライブラリを用いますが,予めターミナル上でこのように宣言する必要があります.
$ sudo pigpiod# -*- coding: utf-8 -*-
import pigpio
import time
import cv2
import sys
import numpy as np
import picamera
import picamera.array
from scipy import stats
from sklearn.neural_network import MLPClassifier
from sklearn.externals import joblib
version = cv2.__version__.split(".")
CVversion = int(version[0])
# 学習に用いる縮小画像のサイズ
sw = 16
sh = 12
#正解クラス
shape_class = ['right', 'left', 'up', 'down', 'back']
#servo setup
gpio_pin_h = 18
gpio_pin_v = 19
pi = pigpio.pi()
pi.set_mode(gpio_pin_h, pigpio.OUTPUT)
pi.set_mode(gpio_pin_v, pigpio.OUTPUT)
# 学習済ファイルの確認
if len(sys.argv)==2:
savefile = sys.argv[1]
try:
clf = joblib.load(savefile)
except IOError:
print('学習済ファイル{0}を開けません'.format(savefile))
sys.exit()
else:
print('使用法: python vision_recognition.py 学習済ファイル.pkl')
sys.exit()
##########################################################################################
###################################### FUNCTION ########################################
##########################################################################################
def getImageVector(img):
# 白い領域(ピクセル値が0でない領域)の座標を集める
nonzero = cv2.findNonZero(img)
# その領域を囲う四角形の座標と大きさを取得
xx, yy, ww, hh = cv2.boundingRect(nonzero)
# 白い領域を含む最小の矩形領域を取得
img_nonzero = img[yy:yy+hh, xx:xx+ww]
# 白い領域を(sw, sh)サイズに縮小するための準備
img_small = np.zeros((sh, sw), dtype=np.uint8)
# 画像のアスペクト比を保ったまま、白い領域を縮小してimg_smallにコピーする
if 4*hh < ww*3 and hh > 0:
htmp = int(sw*hh/ww)
if htmp>0:
img_small_tmp = cv2.resize(img_nonzero, (sw, htmp), interpolation=cv2.INTER_LINEAR)
img_small[int((sh-htmp)/2):int((sh-htmp)/2)+htmp, 0:sw] = img_small_tmp
elif 4*hh >= ww*3 and ww > 0:
wtmp = int(sh*ww/hh)
if wtmp>0:
img_small_tmp = cv2.resize(img_nonzero, (wtmp, sh), interpolation=cv2.INTER_LINEAR)
img_small[0:sh, int((sw-wtmp)/2):int((sw-wtmp)/2)+wtmp] = img_small_tmp
# 0...1の範囲にスケーリングしてからリターンする
return np.array([img_small.ravel()/255.])
# サーボモータの制御
duty_max = 120000 #12%
duty_min = 20000 #2%
step = int((duty_max - duty_min) / 20)
duty_h = 70000
duty_v = 70000
def servo_control(mode):
global duty_h
global duty_v
if mode == 0 and duty_h != duty_max: # right
duty_h += step
elif mode == 1 and duty_h != duty_min: #left
duty_h -= step
elif mode == 2 and duty_v != duty_min: #up
duty_v -= step
elif mode == 3 and duty_v != duty_max: #down
duty_v += step
elif mode == 4: #back
pass
# PWM OUT
pi.hardware_PWM(gpio_pin_h, 50, duty_h)
pi.hardware_PWM(gpio_pin_v, 50, duty_v)
############################################################################################
################################### ACTION ###############################################
############################################################################################
print('認識を開始します')
with picamera.PiCamera() as camera:
with picamera.array.PiRGBArray(camera) as stream:
# カメラの解像度を320x240にセット
camera.resolution = (320, 240)
# カメラのフレームレートを15fpsにセット
camera.framerate = 15
# ホワイトバランスをfluorescent(蛍光灯)モードにセット
camera.awb_mode = 'fluorescent'
while True:
# stream.arrayにBGRの順で映像データを格納
camera.capture(stream, 'bgr', use_video_port=True)
# 映像データをHSV形式に変換
hsv = cv2.cvtColor(stream.array, cv2.COLOR_BGR2HSV)
# 取り出す色を指定
lower_green = np.array([40,50,50])
upper_green = np.array([70,255,255])
#マスク処理
mask = cv2.inRange(hsv, lower_green, upper_green)
# 以下、最も広い白領域のみを残すための計算
# まず、白領域の塊(クラスター)にラベルを振る
if CVversion == 2:
img_dist, img_label = cv2.distanceTransformWithLabels(255-mask, cv2.cv.CV_DIST_L2, 5)
else:
img_dist, img_label = cv2.distanceTransformWithLabels(255-mask, cv2.DIST_L2, 5)
img_label = np.uint8(img_label) & mask
# ラベル0は黒領域なので除外
img_label_not_zero = img_label[img_label != 0]
# 最も多く現れたラベルが最も広い白領域のラベル
if len(img_label_not_zero) != 0:
m = stats.mode(img_label_not_zero)[0]
else:
m = 0
# 最も広い白領域のみを残す
img_m = np.uint8(img_label == m)*255
# 最大の白領域からscikit-learnに入力するためのベクトルを取得
img_vector = getImageVector(img_m)
# 学習済のニューラルネットワークから分類結果を取得
result = clf.predict(img_vector)
# 分類結果を表示
print(shape_class[result[0]])
# 得られた二値化画像を画面に表示
cv2.imshow('img_m', img_m)
#servo control
servo_control(result[0])
# 'q'を入力でアプリケーション終了
key = cv2.waitKey(1)
if key == ord("q"):
break
# streamをリセット
stream.seek(0)
stream.truncate()
cv2.destroyAllWindows()ここでも,ニューラルネットワークの学習のときにしたように,取り込んだ画像を16×12の画像データに画像処理をします.これは先ほどのプログラムの使いまわしです.
192個のデータに変換して,clf.predict関数で推測することができます.
ロボットをコントロールしている関数はservo_controlです.duty比を5%~12%の範囲で調整します.一回の認識でstep分角度を変化させます.
一回の認識で9°変化させています.つまり20回同じ方向を認識すれば,180°変化します.
動画とまとめ
実際に動いたものを見ていきましょう.動かしたものはYoutubeにアップしているので,ぜひ見て下さい.
こんな感じで,自分だけのAI画像認識モデルを作って遊ぶことができます.
画像処理や,機械学習などはとっつきにくいですが,これらの本がおすすめです.
この本は、実際にラズベリーパイを使って機械学習をして、何か動く物を作ってみたい方におすすめです.
ラズベリーパイは機械学習を実行するにはスペックがそんなに高くないので、ラズパイでもできる機械学習の方法が書いてある良本です。

こちらの本は機械学習の一種である、ディープラーニングについて、実際に何が行われているかを知りたい方におすすめです。

この本は、機械学習の外観をざっと見てみたい時や、機械学習の中からこんなものをやってみたい!という感じで、やりたいことを探す本として使うのがおすすめです。





前回よりも大分進化したようダナ!
見せてもらおうか,その実力とヤラヲ!