

前回は,scikit-learnのデータセットのアヤメについて,2つの特徴量を用いて2つのクラスに分類し,可視化を行いました.
今回は,2つの特徴量を用いて3つのクラスに分類し,可視化を行いたいと思います.
目次
コード
今回用いるコードは以下のようになります.
from sklearn import datasets, svm
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import colors
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 特徴量を2次元で考えるため.
# sepal length と sepal width を使用
X = X[:, :2]
#サポートベクターマシン
clf = svm.SVC(kernel="rbf", decision_function_shape="ovr")
#学習
clf.fit(X, y)
#------------------------------------------------------------
#背景の色分け
#sepal length と sepal width の最小値,最大値から
#1だけ広げた領域をグラフ表示領域とする
x_min = min(X[:, 0]) - 1
x_max = max(X[:, 0]) + 1
y_min = min(X[:, 1]) - 1
y_max = max(X[:, 1]) + 1
#グラフ表示領域を500*500のグリッドに区切る
XX, YY = np.mgrid[x_min:x_max:500j, y_min:y_max:500j]
#学習モデルに入力するため整形
Xg = np.c_[XX.ravel(), YY.ravel()]
#グリッドの各点を学習モデルで予測
#Zは0~2
Z = clf.predict(Xg)
#グリッド上に並べなおす
Z = Z.reshape(XX.shape)
#クラス0(iris setosa)は黄色
#クラス1(iris versicolor)は灰色
#クラス2(iris virginica)は緑色
cmap0 = colors.ListedColormap([(0, 0, 0, 0),"yellow"])
cmap1 = colors.ListedColormap([(0, 0, 0, 0),"gray"])
cmap2 = colors.ListedColormap([(0, 0, 0, 0),"green"])
#背景の色の表示
plt.pcolormesh(XX, YY, Z==0, cmap=cmap0)
plt.pcolormesh(XX, YY, Z==1, cmap=cmap1)
plt.pcolormesh(XX, YY, Z==2, cmap=cmap2)
plt.xlabel("sepal length")
plt.ylabel("sepal width")
#----------------------------------------------------------
#データ点の色つけ
#分類に応じたデータを取り出す
X0 = X[y==0]
X1 = X[y==1]
X2 = X[y==2]
#iris setosaのデータをプロット
plt.scatter(X0[:,0], X0[:,1], c="yellow", linewidths=0.5, edgecolors="black")
#iris versicolorのデータをプロット
plt.scatter(X1[:,0], X1[:,1], c="gray", linewidths=0.5, edgecolors="black")
#iris virginicaのデータをプロット
plt.scatter(X2[:,0], X2[:,1], c="green", linewidths=0.5, edgecolors="black")
#サポートベクトルを取得
SV = clf.support_vectors_
#サポートベクトルをプロット
plt.scatter(SV[:,0], SV[:,1], c=(0,0,0,0), linewidths=1.0, edgecolors="red")
plt.show()このコードは 『Raspberry piではじめる機械学習』を参考にしたものです.
以下のサイトでソースコードをダウンロードできます.
http://bluebacks.kodansha.co.jp/books/9784065020524/appendix/
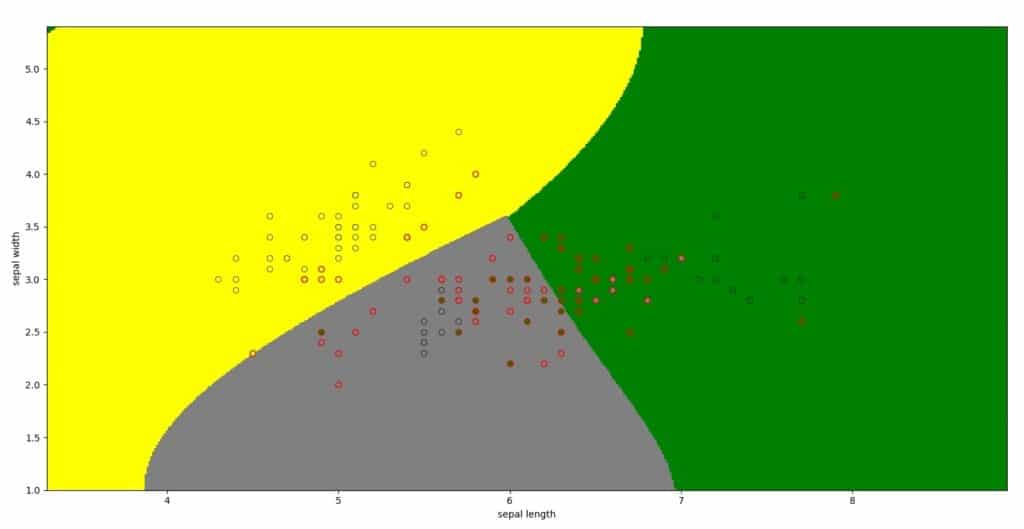
結果
上記のコードの結果はこのようになります.
コード解説
用いるデータ
scikit-learnのirisデータは,4つの特徴量がありますが,4次元を表現することができないため,今回は2つの特徴量を用います.
4つの特徴量を2つの特徴量に次元削除を行っているのが,13行目です.
正解ラベルはデフォルトの3つを使うので,変更しません.
サポートベクターマシン
今回はサポートベクターマシンを使って,機械学習を行います.サポートベクターマシンとは,データを分類するために,境界線を超平面で引く分類方法です.
clf = svm.SVC(kernel="rbf", decision_function_shape="ovr")svmモジュールのSVCクラスのインスタンスを生成することで,機械学習オブジェクトが作れます.
kernelが境界線をどのような関数で行うかというもので,今回はrbfという曲線を用いて分類します.ovrは複数のクラスに分類するときに用います.
メッシュグリッドの生成
画像として出力するために,座標を定義する必要があります.
x座標,y座標をメッシュ格子として定義します.numpy.mgridでメッシュ配列を作ります.
mgrid[最小:最大:個数j]で何個メッシュを作るかを指定できます.今回は500×500のメッシュ格子を作ります.
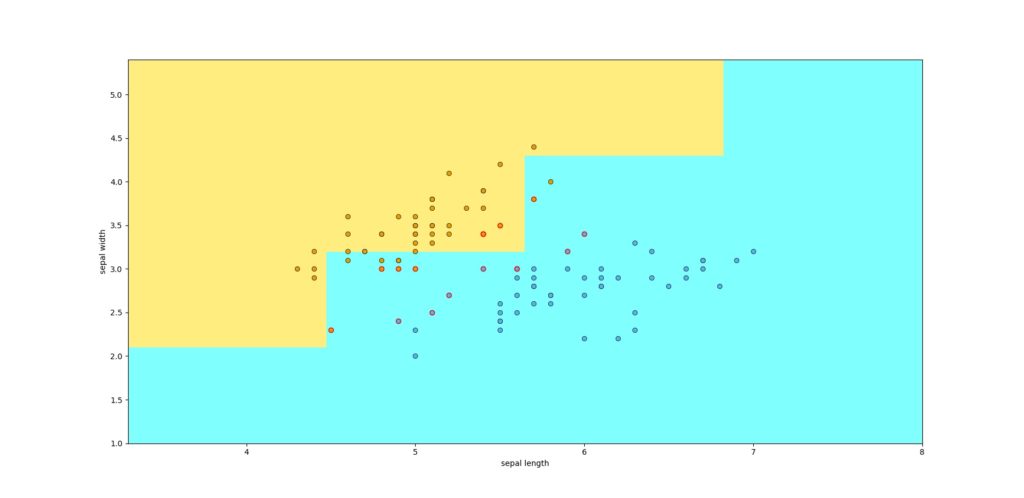
もしこの値が小さすぎると,下の画像のように荒くなります.これは個数を5とした場合です.
XX, YY = np.mgrid[x_min:x_max:500j, y_min:y_max:500j]
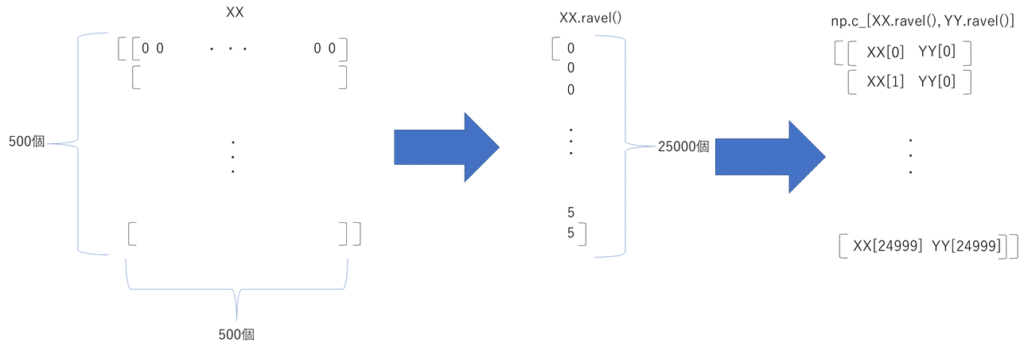
Xg = np.c_[XX.ravel(), YY.ravel()]メッシュデータを学習用の入力データに変換します.
XX,YYはそれぞれ2次元データとなっていて,それぞれを1次元データに変換し,numpy.c_で2つの1次元データを結合します.それによって,すべての座標での予測を学習モデルで実行できます.
※上の画像の一番右の2列目はYY[0]ではなく,YY[1]です.
背景の色つけ
ここから前回と大きく違います.前回は2つのクラスに分けただけでした.つまり,カラーマップはある条件を満たすか満たさないかだけで判断できました.
今回は3つに分ける必要があるため,ある条件を満たすかという判断(Z==0 or Z==1 or Z==2)をそれぞれでする必要があります.
cmap0 = colors.ListedColormap([(0, 0, 0, 0),"yellow"])
cmap1 = colors.ListedColormap([(0, 0, 0, 0),"gray"])
cmap2 = colors.ListedColormap([(0, 0, 0, 0),"green"])
plt.pcolormesh(XX, YY, Z==0, cmap=cmap0)
plt.pcolormesh(XX, YY, Z==1, cmap=cmap1)
plt.pcolormesh(XX, YY, Z==2, cmap=cmap2)pcolormeshが,色をつける関数ですが,メッシュ格子に従い下の図のように色をつけます.
(X[i+1, j], Y[i+1, j]) (X[i+1, j+1], Y[i+1, j+1])
+——–+
| C[i,j] |
+——–+
(X[i, j], Y[i, j]) (X[i, j+1], Y[i, j+1]),
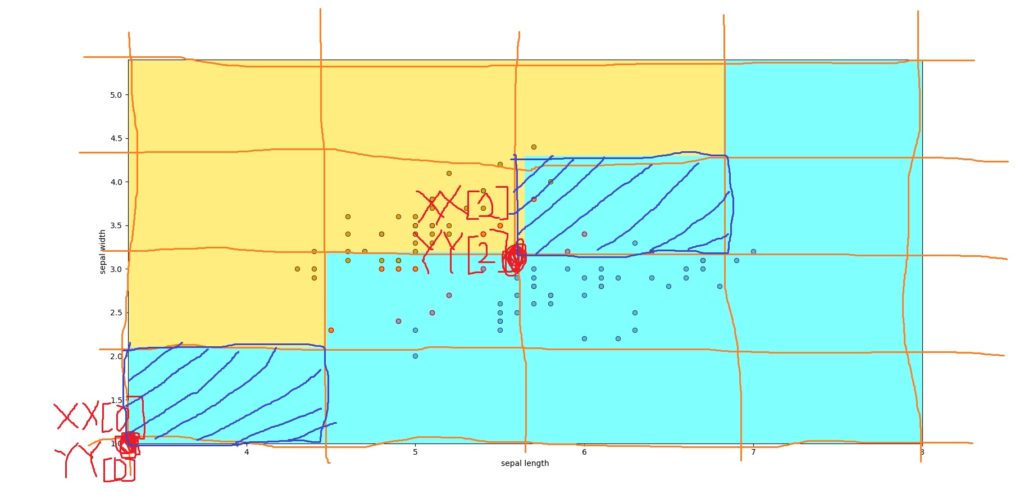
上の図は5*5のメッシュに色をつけた場合です.このように,一つの点に対して持っている領域に色を塗っています.
点のプロット
#分類に応じたデータを取り出す
X0 = X[y==0]
X1 = X[y==1]
X2 = X[y==2]
#iris setosaのデータをプロット
plt.scatter(X0[:,0], X0[:,1], c="yellow", linewidths=0.5, edgecolors="black")
#iris versicolorのデータをプロット
plt.scatter(X1[:,0], X1[:,1], c="gray", linewidths=0.5, edgecolors="black")
#iris virginicaのデータをプロット
plt.scatter(X2[:,0], X2[:,1], c="green", linewidths=0.5, edgecolors="black")ここの部分で点のプロットを行っています.
まず3種類にデータ点を分けて,scatterで散布図を描きます.
サポートベクトルのプロット
#サポートベクトルを取得
SV = clf.support_vectors_
#サポートベクトルをプロット
plt.scatter(SV[:,0], SV[:,1], c=(0,0,0,0), linewidths=1.0, edgecolors="red")境界線を引くときに用いるサポートベクトルをプロットします.clf.support_vectors_でデータ点を取り出すことができます.
先ほどのデータ点は黒色でプロットしたので,目立つように赤色でプロットします.
まとめ
今回は,前回行った2特徴量2分類を拡張して,2特徴量3分類をやってみました.
自分自身も機械学習を勉強中ですが,良い本を見つけることが一番早く上達すると思います.
今回のプログラムは以下の本を参考にしたものなので,より機械学習について学んでみたいという方はぜひ読んでみて下さい.

ラズベリーパイを初めて使いたいという方には,こちらの本がおすすめです.

次の記事
次回はニューラルネットワークを用いた分類についてまとめます.







コメントを残す